Leveraging Value from Data
How can asset-related data be converted into sustainable business intelligence?
Data on assets arises routinely from business operations and maintenance and provide the basis for analysing investment and budget needs. Since it is costly, managing data holdings is yet another risk-based decision that must be carefully weighed. The implication of getting this decision wrong can have long-term implications to the bottom-line and service provision.

The actual cost of poor data is open to debate, but a lower end estimate was provided by English (1998), who concluded that the business costs of non-quality data may be as high as 20% of the total budget of an organization. While that might seem high, it reflects such things as non-recoverable costs, rework, workarounds, lost and missed revenue, and sub-optimal investment decisions that do not deliver the benefits promised.
Asset-rich businesses should thus be able to achieve relatively short pay back periods from investments in data improvements. However, many such initiatives fail to deliver on their promises. We advise piloting decision support systems to ensure they add business value, then use the insights gained as a motivation to collect better data in a targeted manner.
We also advise adopting an iterative approach to decision support that uses best available data in the first instance (usually that held on corporate systems), which can then be augmented as needed via condition assessment, survey work, and judicious use of modelling/analytics.
This philosophy is a key design feature of the PARMS decision support suite.
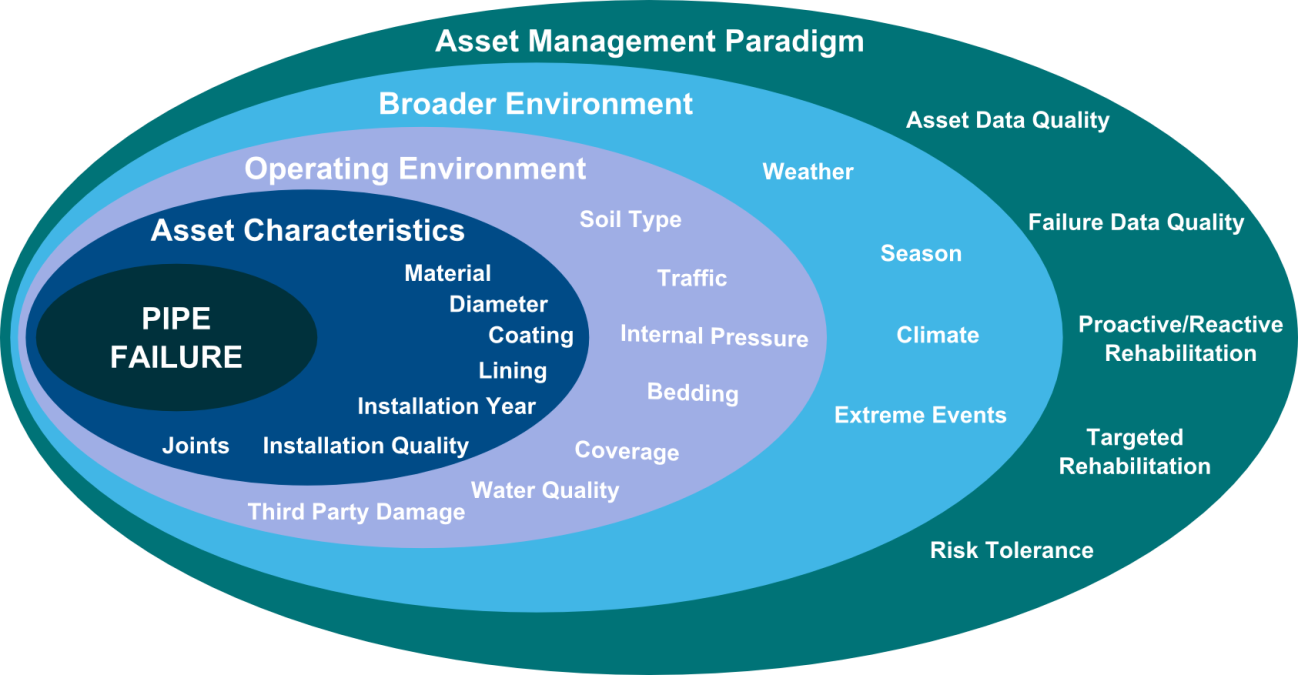
The Data Value Chain

It is said that utilities are data rich but information poor. This situation can be contrasted with the idealised data value chain, which highlights the need to analyse data to provide targeted information. This then helps build corporate knowledge and wisdom:
- Data: facts and statistics collected together for reference or analysis.
- Information: what is conveyed by a particular arrangement or sequence of data
- Knowledge: understanding gained by experience of a fact or situation
- Wisdom: good judgement based on generated knowledge
Realising the data value chain effectively is non-trivial and requires business as usual data collection and management protocols to be implemented. In particular, data needs to be fit for purpose and available for use without necessitating months of effort to collate and cleanse data held on disparate systems, and even personal spreadsheets.
Fortunately, a shrewd upfront investment can avoid most if not all of these costs and save money over the medium to long term.
The law of diminishing returns implies that there is an economic level of data improvement, which occurs when the marginal cost of that improvement is equal to the marginal benefit of the improved data. In particular, the value of data in terms of improved decision making needs to be considered.
Avoiding Dumb Analytics
A critical implication of the data value chain is that the quality of data available dictates the level of modelling that is justified. We advise being at least wary of analytical techniques that ignore GIGO concepts (garbage in, garbage out)
Machine learning and optimisation techniques in particular can be applied to any dataset irrespective of its quality. The results may seem enticing, but in reality, poor quality data cannot be transformed into meaningful business intelligence.
Gold may come from dirt, but you can’t make dirt into gold. Hence, while it may be appealing to assume asset management decisions can be left to complex IT solutions, without underpinning data and supporting institutional capacity, all that really does is give the impression of enabling the data-value chain.
We use the acronym DATA to emphasise this trap... Dumb Analytics That Allure.
What is actually needed are solutions that are grounded in engineering, business, and scientific realities. IT solutions are part of the answer, they are just not the answer.
In other words, buyer beware...
Avoiding Generic Data When Possible
In Australia, the USA and the UK, there have been various initiatives to bring together datasets for water pipes and other asset classes. Unfortunately, this reflects a misapprehension over how data is collected and its broader applicability.
Our work has shown there is significant variability in data holdings across different water and environmental businesses. A data item may be called the same thing but be defined very differently.
The specification for data used in many of these data integration projects is also generally incomplete; for example, attributes like soil or pressure were not broadly available and so were missing from the generic datasets. In our experience, it is thus necessary to use utility-specific rather than generic data whenever possible and to use modelling tactics like sensitivity analysis where this cannot be achieved.